
Background
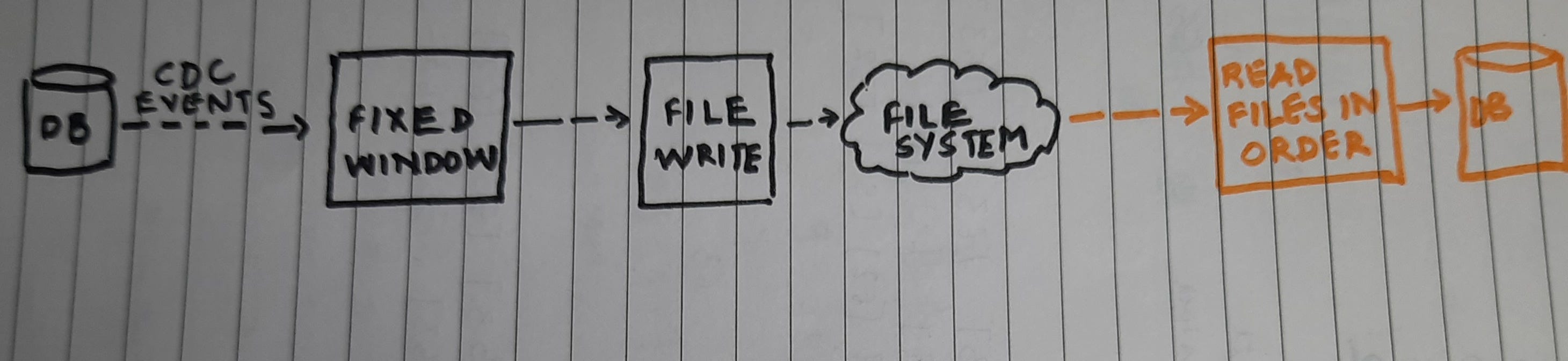
I needed a streaming pipeline to replicate data from one database to another. It was a heterogeneous replication, the two databases were of different vendors. The source database CDC events were streamed and split into fixed windows . This neatly split CDC data was written to files. The second streaming pipeline would read the file in temporal order and convert it’s data to target database schema and write to database.
Now, in order to understand the problem, we need to understand file creation semantics.
File creation semantics
The file created would have the window name, something like below which represents a 5 second interval
2023-08-11T06:45:00-2023-08-11T06:50:00.txtIf, for a given interval, there is no CDC data, no file is created.
Apache Beam model, does not guarantee that the window intervals will be processed in order. It is possible that multiple windows get manifested at once and then these windows can get processed in parallel. [ Wonderful video ].
This means that - I could have a file with a later interval interval being written before an earlier interval.
The second pipeline looks up the file system per timer interval , generates the file name for a given interval, based on the previously read interval and does a file lookup with the generated name.
Problem statement
Did you guess it already?
Well, in my second pipeline when I lookup file for a given interval - and I do not find it, then I do not know if it’s because there was no CDC data for that interval OR if the file is still being written by the first pipeline.
Solution Options
Reading files differently
In the second pipeline, instead of handcrafting the file names and doing a lookup, I could have used the continuous file read option, which would give me a PCollection of file names that got generated since my last lookup.
There were some problems with this:
The PCollection of file names is not ordered. In order to process them in parallel - I would need to have another state-timer based logic to store the files names, sort them and then apply my logic. While all this is doable - it is quite cumbersome.
If the second pipeline is restarted, there is no way to start reading the file system from a given file creation pattern onwards. Which means - to read all the file names and discard until I have reached the file name that matches my last successful progress point. Highly inefficient.
Track the progress of first pipeline in a table
The idea was, in the first pipeline, I will track the maximum interval processed thus far in a table. If the second pipeline does not find a file - it will check if the first pipeline has progressed beyond the interval or not.
There were following problems though:
Since files of different intervals can be written in parallel - there is no good way to track this progress when writing the files.
There is no way get watermark of the step in a DoFn or Transform. ( Why?!?) It could have been infinitely easier to just take this watermark and write to the table.
So what are we solving finally?
The essence of the problem am trying to solve is - given fixed windows being processed, how to get the watermark of the processing being done?
Voila
I used double windowing.
The getPerDestinationOutputFilenames function gives the PCollection of file names written. These PCollection have the window information.
I then created another fixed windows out of these PCollections - which gave the a definite watermark to work with. The first pipeline now looked like below:
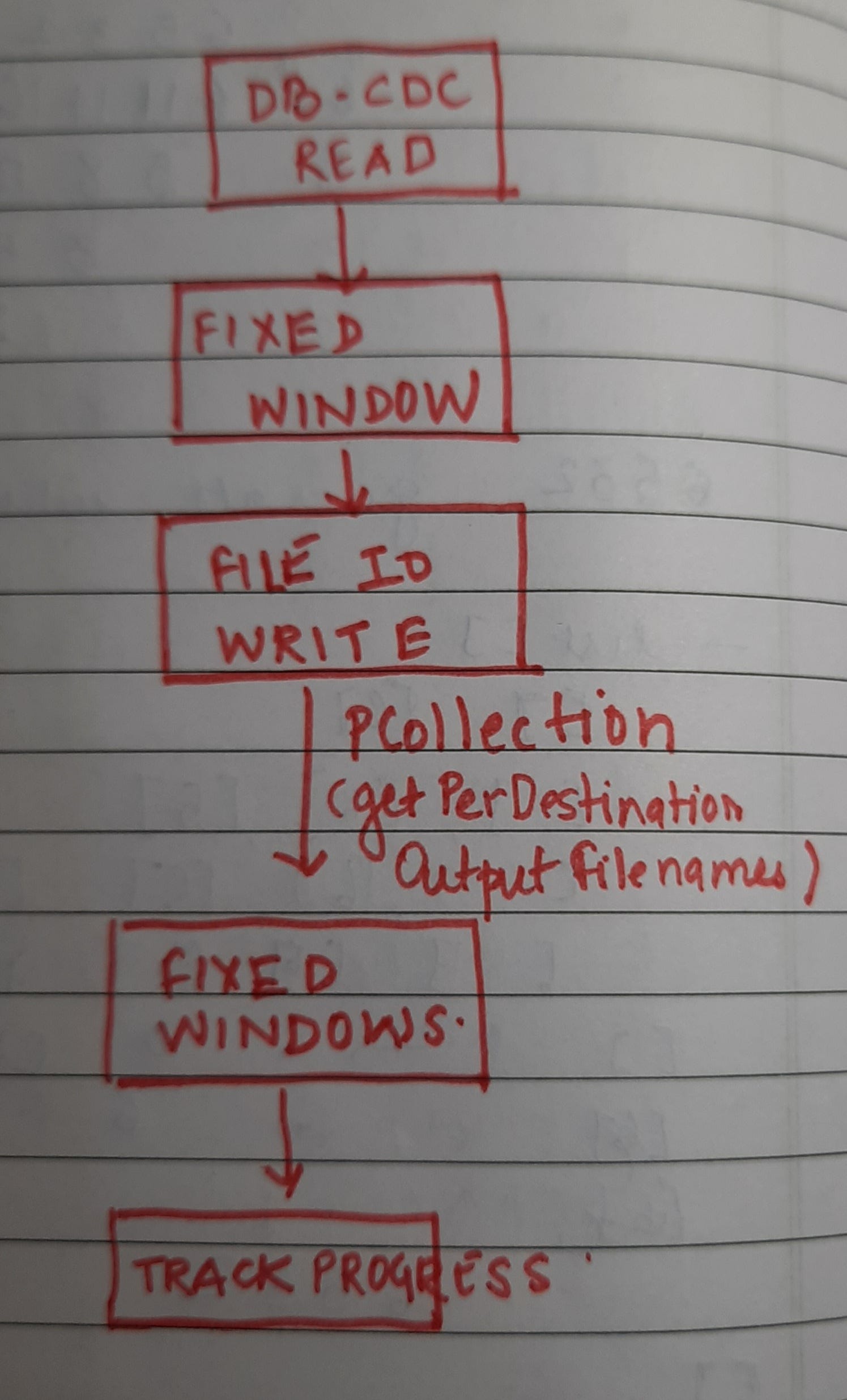
The TrackProgress gets the BoundedWindow - which I used to track the time until which files are guaranteed to be written.
State and timer
A failed approach here was - having a DoFn with state and timers, storing the file name in state and then setting timer to the window end plus some duration.
This did not work since, the fixed widows created to split the CDC did not allow for any lateness. Even creating new windows after file writing with allowed lateness did not work
Hence I did not use state and time for a bounded window - rather used a simple PTransfrom.
Takeaway
Until the SDK gives a programmatic way to get the step’s watermark - one can get the watermarks of the previous steps by using windowing and then triggering the functions off of it.